考虑这样的代码:
std::cout << std::setw(20) << std::right << "测试abcカキクケコ" << std::endl;
std::cout << std::setw(20) << std::right << "测试abc测试" << std::endl;使用 UTF-8 编译,在 Windows (MSVC)与 Linux(GCC)上均产生了这样的结果:

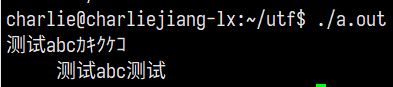
显然,这两行文本均没有被正确对齐。这是因为 UTF-8 下中文等CJK字符通常占用 3 个字节,但中文在控制台下占据 2 个字符的位置。这种情况下系统直接把字节数作为宽度格式化就会出现错位的现象。
===20220204 更新=== 我已经把完整的结局方案代码和下一篇文章的另一个问题的方案一起放在了 GitHub 上,如果想快速解决问题可以移步这个 repo:https://github.com/cqjjjzr/utf8-console
这个问题是高级程序设计课上一个同学问我的。显然也只有这种课的 Project 会要求我们在控制台下手搓一个 CLI 还要处理中文。。。
如果用 GB-18030(GBK) 编码,这种情况不会出现,这源于一个巧合:在 GBK 编码中中文通常占用 2 字符,恰好和控制台下中文占 2 字符的事实对应。然而,依赖这样的巧合是不健壮的,如果包含半角日语字符、西里尔字符、希腊文字符等,这样的巧合就无法成立。例如上面代码在 GBK 编码下仍会因为第一行的半角日语文本错位。
为了解决这个问题,我们需要在设置场宽时考虑“字符”(char)数和字符实际宽度的差别。在 Linux 等平台上有“wcwidth”与“wcswidth”分别测量一个宽字符在控制台下的“宽度”。因此我们易得式子:
设置场宽 = 目标场宽 + (字符 char 数 - 字符实际宽度)其中的“场宽”都以半角宽度为单位。
然而,我们面临两个问题:
wcswidth函数仅在 Linux 下提供- 我们的文本是 UTF-8 编码的,而不是“宽字符”(Linux 下通常为 UCS-4,Windows 下通常为 UTF-16)
对于第一个问题,剑桥大学的 Markus Kuhn 提供了一段简短的、portable 的代码,让我们可以在代码中直接嵌入 Termux 的 wcwidth 更新一些,支持 emoji。wcwidth 函数。
对于第二个问题,解决方案多如牛毛:
- 使用平台相关的解决方案(
MultiByteToWideChar、iconv、icu等),但对于解决这样一个小问题而言,这种方案未免过于庞大 - 引入 UTF8-CPP 库来处理
这里使用第二种解决方案:使用 UTF8-CPP 来将 UTF-8 串转为 wchar_t。然而,需要注意的是,Windows 上的宽字符是 UTF-16,但上面的 wcwidth 函数不支持 4 字节 UTF-16,因此在遇到 emoji 时这个方案会歇菜(实际不会,wcwidth 会把组成一个 emoji 的两个 UTF-16 码元分别认为是 1 宽度的,那两个正好就是 2 宽度,和控制台上的宽度对应,只能说奇妙的巧合)。
(反转了,emoji 在 Unicode 5.2 才引入,而这个 portable 的 wcwidth 只支持到 Unicode 5.0,因此会把 emoji 认成 1 字节,在 UTF-32 环境下反而歇菜了😅😅)
(换了支持更新 Unicode 的 wcwidth 实现,现在能正确处理 wcwidth 了)
同时,UTF8-CPP 的转换函数还有一些好特性:支持直接传入一个 OutputIterator 作为输出。因此我们可以写一个自定义的 Iterator 避免真正把字符串转出来,省下了开内存空间的时空资源。下面的完整代码中我直接写了一个“setw_u8”函数替代原来的 std::setw 函数。
// 也可以写一个单独的 header,这里省了
extern "C" int wcwidth(int ucs); // 接受的是一个 Unicode Code Point!
// 自定义的 iterator,不用实际保存宽字符串了!只需要记录场宽
class wcswidth_iterator
{
private:
size_t _result = 0;
public:
size_t result() const { return _result; }
void reset() { _result = 0; }
// 20220224 更新:wchar_t -> int,换掉了 wcwidth 的实现
wcswidth_iterator& operator=(wchar_t value)
{
auto len = wcwidth(value);
if (len < 0)
throw std::runtime_error("Invalid UTF-8 value");
_result += len;
return *this;
}
wcswidth_iterator& operator*() { return *this; }
wcswidth_iterator& operator++() { return *this; }
wcswidth_iterator& operator++(int) { return *this; }
};
size_t utf8_cswidth(std::string_view str)
{
// 20220224 更新:何不一律使用 UTF-32,去掉 wchar_t 并换成 int 表示呢
return utf8::utf8to32(str.begin(), str.end(), wcswidth_iterator()).result();
// if constexpr (sizeof(wchar_t) == 4)
// {
// // Linux 上的 UTF-32
// return utf8::utf8to32(str.begin(), str.end(), wcswidth_iterator()).result();
// }
// else
// {
// // Windows 上的 UTF-16
// return utf8::utf8to16(str.begin(), str.end(), wcswidth_iterator()).result();
// }
}
decltype(std::setw(0)) setw_u8(int w, std::string_view u8s)
{
try
{
return std::setw(w + u8s.length() - utf8_cswidth(u8s));
} catch (std::runtime_error&)
{
return std::setw(w);
}
}使用例:
std::string str("测试abcカキクケコ");
std::string str2("测试abc测试");
std::cout << std::right << setw_u8(20, str) << str << std::endl;
std::cout << std::right << setw_u8(20, str2) << str2 << std::endl;效果如图:


注意,在用 UTF-8,你需要注意以下几点:
- 源代码使用 UTF-8 编译:MSVC 需要打开
/utf-8开关 - 源代码使用 UTF-8 编写
- Windows 下需要将控制台代码页改为 65001:可使用
system("chcp 65001");,更优雅的做法是用SetConsoleOutputCPWindows API。
延伸阅读
https://stackoverflow.com/questions/29188948/cout-setw-doesnt-align-correctly-with-%C3%A5%C3%A4%C3%B6
https://man7.org/linux/man-pages/man3/wcswidth.3.html
https://stackoverflow.com/questions/15114303/determine-whether-a-unicode-character-is-fullwidth-or-halfwidth-in-c
http://www.unicode.org/reports/tr11/
Comments NOTHING