

本文首发于本人知乎帐号,现转到 blog 上.
Java 1.3 的时候出了个 Java Sound 功能,可以平台无关地调用系统底层 API 播放声音等等,甚至通过 JMF(Java Media Framework,已经差不多死了) 实现解码等功能。
解决过程
测试环境:
- Windows 10 Build 16226 简体中文版
- Java Development Kit 8u131(对照组) & OpenJDK 9 EA(实验组)
- IntelliJ IDEA 2017.1
- Visual Studio 2015(调试) & 2010(编译)
最近我在写某个 Project 的时候想用 Java Sound 播放从 FFmpeg 解码出来的 PCM 数据。其中我想让用户选择声卡,于是照着网上的某个范例写了这么一些代码(Kotlin的,凑合着看):
AudioSystem.getMixerInfo().forEach {
println("info: " + it.toString())
AudioSystem.getMixer(it).apply {
println("output " + this)
sourceLineInfo.forEach {
println(" info: " + it.toString())
AudioSystem.getLine(it).apply {
if (this is SourceDataLine) {
(this.lineInfo as DataLine.Info).formats.forEach {
println(" format: " + format.toString())
}
}
}
}
}
println()
}
上面这段代码会罗列出所有系统中的输出设备,但是执行却得出了这样的效果(部分):
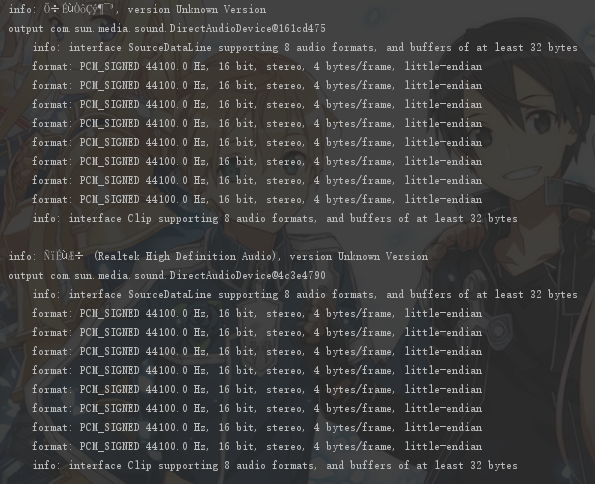

设备名称变成了乱码。但是如果把这些乱码拷到Notepad++里面会发现根本没办法转换,无论如何都是乱码。同时也与锟斤拷等 UTF-8 字符被用 GBK 解释时出现的乱码不同。并且无法用 Java 中出字符集问题时候的各种解决方法(修改 file.encoding,chcp 修改控制台字符集,等等)解决。
于是就去群里问。然后就出现了dalao!@dram 大佬!
我们用2进制模式查看第一串乱码:


熟悉 Unicode 那一套理论的可能发现这个编码看起来有点像 UTF-8 编码过的双字节字符,110xxxx 10xxxxxx两个字节一个字符。我们按照这种方法提取,得到了这样一组数据:00011010110 00011110111 00011001001 00011111001 00011010010 00011110100 00011000111 00011111101 00010110110 00010101111 00010110011。
去掉前导0,得到:11010110 11110111 11001001 11111001 11010010 11110100 11000111 11111101 10110110 10101111 10110011,换成16进制:d6 f7 c9 f9 d2 f4 c7 fd b6 af b3,输进16进制编辑器里面:


然后换到普通编辑器,用ANSI(中文Windows上就等于GBK)编码打开,发现出现了正确的字符!


原来这串乱码是被UTF-8编码的GBK字符串!
然后我就写了一个简单的函数来修复这个问题:
private val HIGH_IDENTIFY = 0b11000000.toByte()
fun javaSoundRecoverMessyCode(string: String): String {
return String(ArrayList<Byte>().apply buf@ {
string.toByteArray().apply {
var i = 0
while (i < this.size) {
if ((this[i] and HIGH_IDENTIFY) == HIGH_IDENTIFY) {
this@buf += (this[i].toInt() shl 6 or (this[i + 1].toInt() shl 2 ushr 2)).toByte()
i++
} else {
this@buf += this[i]
}
i++
}
}
}.toByteArray(), Charset.forName(System.getProperty("file.encoding")))
}
写的可能比较丑,不要在意。但是我发现了几个问题:
- 看上面的16进制恢复过程就能发现有一些字节丢失;
- 总在代码里面带着这样一个如此丑陋的方法又不好;
- 上面的代码依赖了
file.encoding环境属性,这个属性必须是系统的ANSI对应的字符集,如果有人(没错就是IDEA)将这个属性设置成了UTF-8之类的就没法判定系统字符集,造成无法修复; - 肯定有别的人踩坑!
所以我就去锤 Oracle,最开始发了一个Bug Report,但是那边一直说没法reproduce这个问题,经过几轮邮件交流之后发现他们确实缺少调试环境。然后就这样拖了俩月。那边一直不温不火的。(那时候我和他们都没有意识到,这个不仅仅是中文OS的问题,CJK乃至所有非ASCII的语种都有这个问题)
然后我觉得不能忍了,就决定自己开始Hack。经过几天痛苦的Clone,我从JDK9仓库拿到了OpenJDK的代码(垃圾Hg)。然后顺着Java端代码一路查,查到com.sun.media.sound.DirectAudioDevice这里发现DirectAudioDeviceInfo是从native代码创建的:
![]()

继续查。根据直觉,代码应该在jdk/src/java.desktop下面的某个地方。直接notepad++在文件中搜索方法名,找到了在DirectAudioProvider.c里面:


继续排查,发现这里用了一个NewStringUTF,这个函数会接受一个“改良UTF-8”字符串,记录下来,继续排查:
![]()

接下来看到desc来自这个函数
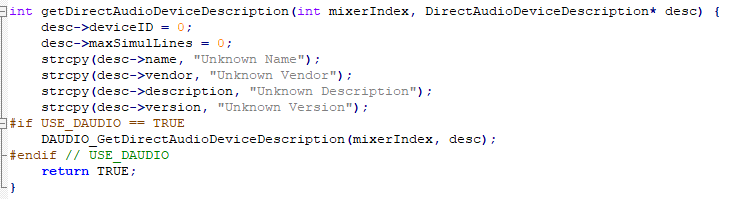

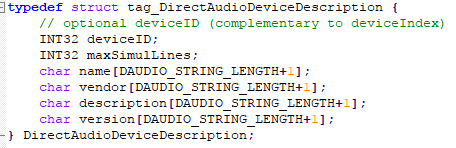
DirectAutioDescription是一个结构体,查看定义(在DirectAudio.h中)可以发现其中name就是一个char[]。

跟着上面的函数,DAUDIO_GetDirectAudioDeviceDescription来自DirectAudio.h,看JavaDoc可以发现DirectAudio是sun弄的一种相当于直接访问音频硬件的功能,所以必定是平台相关的了。那跟着Windows找呢,果然,在jdk/src/java.desktop/windows/native/libjsound/里面,PLATFORM_API_WinOS_DirectSound.cpp有实现。在大约246行:
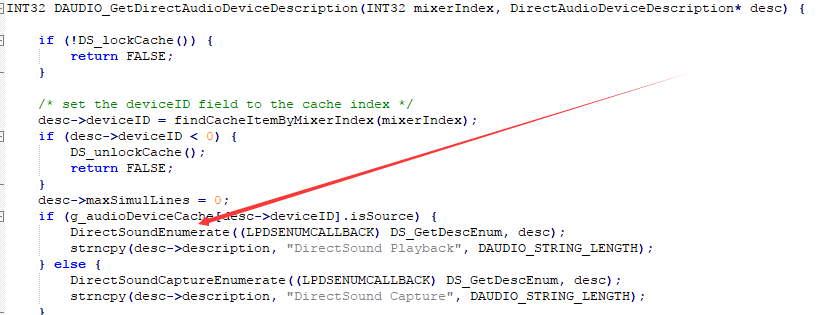

这里涉及到了一点DirectSound(名字很相像,DirectAudio是Java的东西,DirectSound是M$的东西)的知识。简单来说就是DirectSoundEnumerate会回调某个函数来枚举每个音频设备。上面的代码可以看到回调的函数是DS_GetDescEnum,观察这个函数。
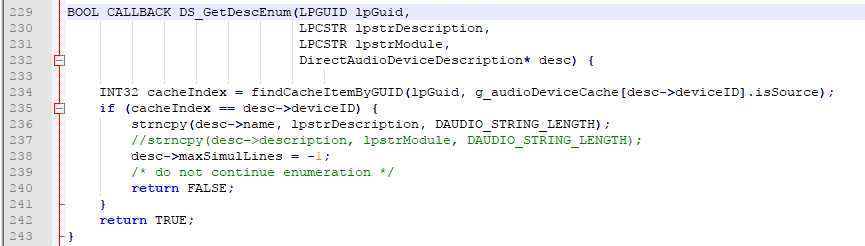

显然,传进来的lpstrDescription就是设备名称。这里直接将其拷贝进了desc->name里面。问题来了,在ASCII的上下文里面,可以直接拷贝,但是如果是非ASCII,可能会包含别的字符。后面我们会了解到JDK编译多半是用的多字节模式,这样DirectSoundEnumerate=DirectSoundEnumerateA,使用ANSI字符集(Windows 下对应 GBK)。问题来了,还记得前面如何将这个LPCSTR(也就是char*)格式的字符串传进虚拟机的吗?对,NewStringUTF!我们看看这个函数的文档:


问题明了了,JVM以为这个desc->name是以“改良UTF-8”编码的Unicode字符串,但实际上它是GBK字符串。所以JVM发现其不是UTF-8,就直接把GBK字符集的字符串编码成了UTF-8。那么这个字符串就彻底崩坏了,变成了UTF-8编码的GBK字符串。
那么如何解决呢?写一个函数把ANSI(中文 Windows 中的GBK)转换为UTF-8即可。本来可以转换成UTF-16然后丢给NewString函数,但是为了尽可能少修改API,我们就通过WIndows API把ANSI转换为UTF-16宽字符,再转换为UTF-8,就像下面那样:
LPCSTR ANSIToUTF8(const LPCSTR& lpAnsiStr)
{
// ANSI -> Unicode
DWORD dwAnsiLen = strlen(lpAnsiStr);
DWORD dwUnicodeLen = ::MultiByteToWideChar(CP_ACP, 0, lpAnsiStr, -1, NULL, 0);
LPWSTR lpUnicodeStr;
lpUnicodeStr = new WCHAR[dwUnicodeLen];
memset(lpUnicodeStr, 0, (dwUnicodeLen) * sizeof(WCHAR));
MultiByteToWideChar(CP_ACP, 0, lpAnsiStr, -1, lpUnicodeStr, dwUnicodeLen);
// Unicode -> UTF8
LPSTR lpUTF8Str;
DWORD dwUTF8Len;
dwUTF8Len = WideCharToMultiByte(CP_UTF8, 0, lpUnicodeStr, -1, NULL, 0, NULL, NULL);
lpUTF8Str = new CHAR[dwUTF8Len];
memset(lpUTF8Str, 0, sizeof(CHAR) * (dwUTF8Len));
WideCharToMultiByte(CP_UTF8, 0, lpUnicodeStr, -1, lpUTF8Str, dwUTF8Len, NULL, NULL);
delete lpUnicodeStr[];
return lpUTF8Str;
}
当然这个代码风格可能很难看,但是还是可以解决问题的。在调试这个并准备修改DS_GetDescEnum时候的时候我又发现了另外一个问题,如果是在Unicode模式下编译,那么DirectSoundEnumerate就等于DirectSoundEnumerateW,这其中会传一个UTF-8编码的Unicode字符串作为参数(2021/03 注:实际上这里理解错误了,JDK没有开启 UNICODE 宏,并且DirectSoundEnumerateW 传的是 UTF-16 字符串)!所以我觉得虽然貌似JDK就是用的多字节模式,但还是判断一下的好,所以最后改成了这样:
BOOL CALLBACK DS_GetDescEnum(LPGUID lpGuid,
LPCSTR lpstrDescription,
LPCSTR lpstrModule,
DirectAudioDeviceDescription* desc) {
INT32 cacheIndex = findCacheItemByGUID(lpGuid, g_audioDeviceCache[desc->deviceID].isSource);
if (cacheIndex == desc->deviceID) {
#ifndef UNICODE
LPCSTR utf8EncodedName = ANSIToUTF8(lpstrDescription);
strncpy(desc->name, utf8EncodedName, DAUDIO_STRING_LENGTH);
delete utf8EncodedName;
#else
strncpy(desc->name, lpstrDescription, DAUDIO_STRING_LENGTH);
#endif
//strncpy(desc->description, lpstrModule, DAUDIO_STRING_LENGTH);
desc->maxSimulLines = -1;
/* do not continue enumeration */
return FALSE;
}
return TRUE;
}
在Unicode模式就不会重新编码。
然后写完之后问题来了,我没法调试。机器上装的Visual Studio 2015,不被OpenJDK支持(2021/03 注:在当时OpenJDK还没有支持新版本VS)。在经历了各种打patch,甚至劫持CL.exe,无数次失败之后,我在昨天晚上选择了放弃,发了一封E-Mail给JSound的Mailing List。顺便还弄了一个Patch,如果各位有兴趣可以过去看看。
今天早上,我觉得不行,还是得自己动手丰衣足食。在another ∞次失败之后,我还是向黑恶势力低头,装了一个VIsual Studio 2010 Express。
又经历了无数次惨痛的修改,终于出了exe,发现一次成功。
接下来就清理一下代码准备发pr吧。下面给一张最终效果图:
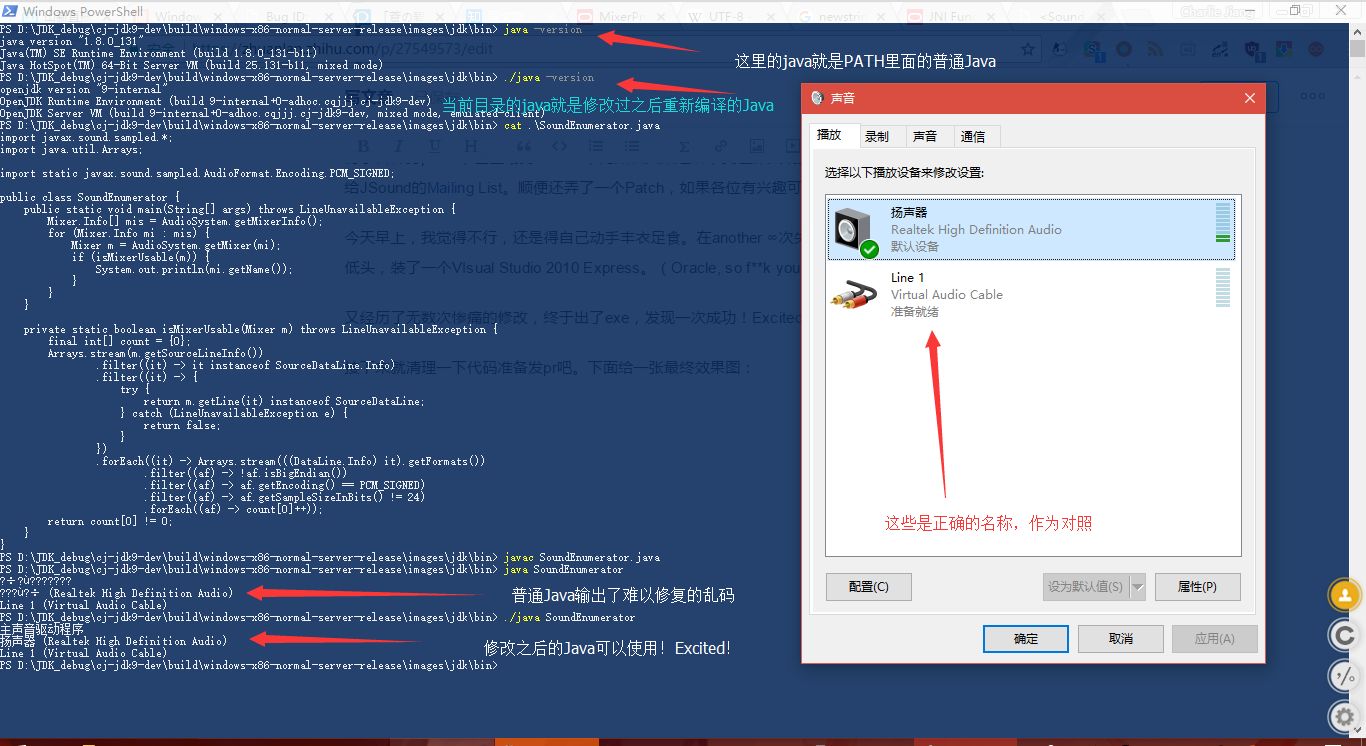

最后我将本 Patch (经过OpenJDK上 reviewer 的指示,做了一些修改)提交到了仓库,并并入 JDK 10 的代码中。
链接
Java Bug Database 上的Bug报告:https://bugs.java.com/bugdatabase/view_bug.do?bug_id=JDK-8177951
Java 的 Mailing List 上对本 Bug 的讨论:
- http://mail.openjdk.java.net/pipermail/sound-dev/2017-June/thread.html
- http://mail.openjdk.java.net/pipermail/sound-dev/2017-July/thread.html
- http://mail.openjdk.java.net/pipermail/sound-dev/2017-August/thread.html
其中标有 8177951 的邮件。最终 Patch 在 http://mail.openjdk.java.net/pipermail/sound-dev/2017-August/000594.html 给出.